
INTRODUCTION
CUDA stands for Compute Unified Device Architecture, and is an extension of the C programming language and was created through nVidia. Using CUDA allows the programmer to take benefit of the big parallel computing power of an Nvidia graphics card in order to do common motive computation.CPUs like Intel Core two Duo and AMD Opteron are good at doing one or two tasks at a time and doing these tasks very quickly. Graphics cards, on the other hand, are right at doing a massive number of tasks at the same time and doing these tasks relatively quickly. To put this into perspective, consider you have a 20-inch monitor with a standard resolution of 1,920 x 1200. An Nvidia graphics card has the computational capacity to calculate the color of 2,304,000 unique pixels, many times a second. In order to accomplish this feat, graphics cards use dozens, even thousands of ALUs. Fortunately, Nvidia’s ALUs are completely programmable, which allows us to harness an extraordinary amount of computational power into the programs that we write.
TOPICS ON CUDA
STRUCTURE
APPLICATIONS
MEMORY AND CACHE ARCHITECTURE
IMAGE PROCESSING
THREAD SCHEDULING
STRUCTURE OF CUDA
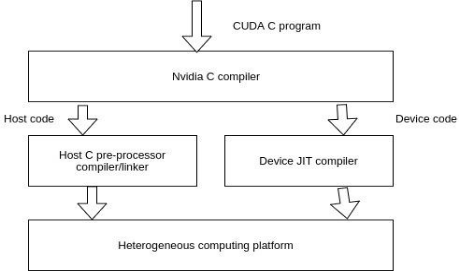
A typical CUDA application has code intended both for the GPU and the CPU. By default, a standard C program is a CUDA program with only the host code. The CPU is referred to as the host, and the GPU is referred to as the device. Whereas the host code can be compiled through a regular C compiler as the GCC, the device code wants a unique compiler to understand the API features that are used. For Nvidia GPUs, the compiler is referred to as the NVCC (Nvidia C Compiler).
The device code runs on the GPU, and the host code runs on the CPU. The NVCC processes a CUDA program and separates the host code from the device code. To accomplish this, unique CUDA keywords are looked for. The code meant to run of the GPU (device code) is marked with different CUDA keywords for labeling data-parallel functions, known as ‘Kernels’. The device code is in addition compiled by the NVCC and executed on the GPU.
APPLICATIONS FOR CUDA
Fast Video Transcoding
Transcoding is a very common, and quite complex method that easily includes trillions of parallel computations, many of which are floating factor operations.
Applications such as Badaboom have been created which harness the raw computing power of GPUs in order to transcode video much faster than ever before. For example, if you prefer to transcode a DVD so it will play on your iPod, it may also take several hours to completely transcode.

Video Enhancement
Complicated video enhancement methods regularly require a huge amount of computations. For example, there are algorithms that can upscale a movie by using data from frames surrounding the current frame. This involves too many computations for a CPU to manage in real-time. ArcSoft was able to create a plugin for its movie player which uses CUDA in order to perform DVD upscaling in real-time! This is a great feat and significantly enhances any movie-watching experience if you have a high definition monitor. This is the best example of how mainstream programs are harnessing the computational power of CUDA in order to delight their customers. Another great instance would be vReveal, which is capable to perform a variety of enhancements to action video, and then save the resulting video.
- Oil and Natural Resource Exploration
Technologies involving oil, gas, and other natural useful resource exploration. Using a variety of techniques, it is overwhelmingly hard to construct a 3d view of what lies underground, especially when the ground is deeply submerged in a sea. Scientists used to work with very small sample sets, and low resolutions in order to locate possible sources of oil. Because the ground reconstruction algorithms are highly parallel, CUDA is perfectly appropriate to this kind of challenge. Now CUDA is being used to find oil sources quicker.
- Medical Imaging
CUDA is a significant development in the field of medical imaging. Using CUDA,
MRI machines can now compute images faster than ever possible before, and for a lower price. Before CUDA, it used to take a whole day to make an analysis of breast cancer. Now with CUDA, this can take 30 minutes. In fact, patients no longer want to wait 24 hours for the results, which will gain many people.
- Computational Sciences
In the raw field of computational sciences, CUDA is very advantageous. For example, it is now possible to use CUDA with MATLAB, which can amplify computations through an incredible amount. Other common tasks such as computing values, or SVD decompositions, or other matrix mathematics can use CUDA in order to speed up calculations.
- Neural Networks
Using the Core two Duo CPU that was accessible, it would have taken over a month to get a solution. However, with CUDA, It is able to decrease time to the solution to under 12 hours.
- Gate-level VLSI Simulation
To create a simple gate-level VLSI simulation device that used CUDA. Speedups were anywhere from 4x to 70x, depending on the circuit and stimulus to the circuit.
- Fluid Dynamics
Fluid dynamics simulations have additionally been created. These simulations require a huge range of calculations and are useful for wing design, and other engineering tasks.
WHY MEMORY AND CACHE ARCHITECTURE IS IMPORTANTUnderstanding how the memory hierarchy and cache structure work is integral to achieving high performance. In the image processing with the SSE article, I show two functions that perform a quick calculation to each pixel in an image, RemoveBlue, and RemoveBlue2. removable processed pixels from top to bottom left to right, and finished in 6.7 milliseconds. RemoveBlue2 processed pixels from left to right, top to bottom, and completed in 0.54 milliseconds. Because RemoveBlue2 processed pixels in a cache pleasant manner, the function executes over 12 times as quick as the non-cache friendly function. A similar phenomenon can also be skilled on GPUs if the cache isn’t used properly.
Basic Memory Hierarchy
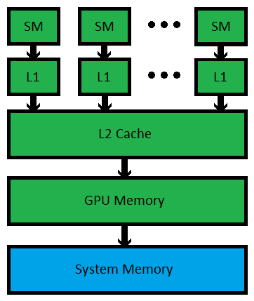
Below is a fundamental design of the memory structure in a modern system using Nvidia’s Fermi architecture. Note that the GPU has its own memory on board. On mid to high-end workstations, this can be anywhere from 768 megabytes all the way up to 6 gigabytes of GDDR5 memory. Typical system memory for computers nowadays ranges somewhere from 6 gigs to sixty-four gigs or more of DDR3 memory for the highest-end workstations. In short, GPUs don’t have as a lot of memory, but the memory bandwidth for GPUs is normally significantly greater than that of even the highest-end Intel or AMD CPUs.
All modern CUDA capable cards (Fermi architecture and later) have a completely coherent L2 Cache. As with memory, the GPU’s L2 cache is a lot smaller than a typical CPU’s L2 or L3 cache but has much greater bandwidth available. Having this L2 cache is incredible for compute applications such as ray tracing, where memory access patterns are very complex and random. Finally, the L1 cache onboard a GPU is smaller than L1 cache in a CPU, but again, it has much higher bandwidth. High-end Nvidia images cards have several streaming multiprocessors or SMs, each is equipped with its very own L1 cache. Unlike most high-end CPUs that have 4 or 6 cores, high overall performance CUDA GPUs have 16 SMs. It is very vital to note that unlike CPU architectures from Intel and AMD, the L1 caches in CUDA capable cards are not coherent. This means that if two unique SMs are reading and writing to the ‘same’ memory location, there is no assurance that one SM will immediately see the modifications from the other SM. These sorts of issues are hard to debug, so you want to think carefully each time you choose two different threads from distinct thread blocks manipulating the same piece of memory.
CUDA FOR IMAGE PROCESSING
A single high definition image can have over two million pixels. Many image processing algorithms require dozens of floating-point computations per pixel, which can end result in slow runtime even for the fastest of CPUs. The slow speed of a CPU is a serious limitation to productivity, as anybody who makes use of Photoshop without a CUDA capable graphics card will tell you. In CUDA, we can commonly spawn exactly one thread per pixel. Each thread will be responsible for calculating the final color of precisely one pixel. Since images are naturally two dimensional, it makes sense to have each thread block be two dimensional. 32×16 is the right size because it permits each thread block to run 512 threads. Then, we spawn as many thread blocks in the x and y dimensions as necessary to cover the entire image. For example, for a 1024×768 image, the grid of thread blocks is 32×48, with each thread block having 32×16 threads.

THREAD SCHEDULING
After a block of threads is assigned to an SM, it is divided into units of 32 threads, each known as a warp. However, the size of a warp depends upon the implementation. The CUDA specification does not specify it.
Here are some important properties of warps :
1. A warp is a unit of thread scheduling in SMs. That is, the granularity of thread scheduling is a warp. A block is divided into warps for scheduling purposes.
2. An SM is composed of many SPs (Streaming Processors). These are the actual CUDA cores. Normally, the variety of CUDA cores in an SM is much less than the total number of threads that are assigned to it. Thus the need for scheduling.
3. While a warp is waiting for the outcomes of a previously done long-latency operation (like data fetch from the RAM), a different warp that is not waiting and is ready to be assigned is selected for execution. This means that threads are usually scheduled in a group.
4. If more than one warps are on the ready queue, then some priority mechanism can be used for assignment. One such technique is round-robin.
5. A warp consists of threads with consecutive threadIdx.x values. For example, threads of the first warp will have threads ids b/w zero to 31. Threads of the second warp will have thread ids from 32-63.
6. All threads in a warp follow the SIMD model. SIMD stands for ‘Single Instruction, Multiple Data’. It is unique when compared to SPMD. In SIMD, each thread is executing the same instruction of a kernel at any given time. But the information is usually different.









